القصة بدأت لما لاحظت اني احتاج تصنيفات فرعيه في اغلب افكار الباك اند على سبيل المثال موقع فيه مسلسلات احتاج تصنيف لفئة المسلسل دراما اكشن الخ.. ثم تصنيف فرعي بالداخل يحتوي على بلد الانتاج ثم مثلا سنة اصدار المسلسل مثال: دراما > تركيا > 2026
او مثلا احتاج اسوي متجر الكتروني واحتاج تصنيفات
مثال:
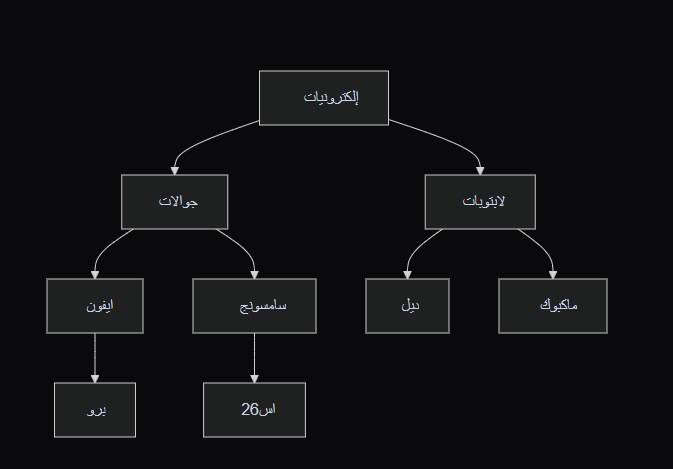
لو تفكر فيها كيف راح اسوي هذي التصنيفات في قاعدة بيانات صفوف واعمدة فقط هل اسوي جدول اسمه category1, category2, category3 ثم اسوي join طريقة تسليكيه جدا وماتنفع
اولاً محتاجين نعرف كيف نمثل التصنيفات في البرمجه قبل قاعدة البيانات اللي محتاجين نمثله مو تصنيفات. بل تسمى شجره
الشجره هي هيكل بيانات ممكن مر عليك لو اخذت مادة هياكل البيانات في الجامعة فكرة الشجره بسيطه هي تشبه الـ linked list
الـ linked list هي ببساطه مجموعة nodes وكل node تأشر على node اخرى واحدة تسمى next pointer بحيث تتمثل مثل المصفوفه ولكن تحل بعض المشاكل الموجوده في المصفوفه العاديه مثل انها تكون ديناميكيه الحجم وليست متصله والاضافه والحذف فيها سريع الخ..
لو عندك linked list معها 2 nodes فهي كأنها شجره لها ابن واحد فقط
الفرق بين الـ tree و الـ linked list هي ان الـ tree تحتوي على node وكل node تأشر على مصفوفه تحتوي على عناوين الابناء كذا صار عندنا شجره!
اسم هذي الشجره N-ary tree يعني تحتوي على عدد n من الأبناء
وهي اللي نحتاجها
بعكس binary tree الشجرة الثنائيه كل node تحتوي على ابنين فقط
import java.util.ArrayList;
import java.util.List;
public class Node<T> {
private T data;
private List<Node<T>> children;
// Constructor
public Node(T data) {
this.data = data;
this.children = new ArrayList<>();
}
public void addChild(Node<T> child) {
this.children.add(child);
}
public T getData() {
return data;
}
public List<Node<T>> getChildren() {
return children;
}
}بكذا تتمثل شجرتنا N-ary tree أستعملت لغة جافا ولكن أي لغة تدعم OOP مثل أغلب لغات البرمجة مثل جافاسكريبت وبايثون و php الخ.. بيكون التمثيل مقارب
وببساطه نقدر ننشئ الشجره مثل كذا:
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
public class ElectronicsStore {
public static void main(String[] args) {
try {
Node<String> electronics = new Node<>("Electronics");
Node<String> mobiles = new Node<>("Mobiles");
Node<String> laptops = new Node<>("Laptops");
Node<String> watches = new Node<>("Smartwatches");
mobiles.addChild(new Node<>("iPhone 15 Pro"));
mobiles.addChild(new Node<>("Samsung Galaxy S24"));
laptops.addChild(new Node<>("MacBook Pro M3"));
laptops.addChild(new Node<>("Dell XPS 15"));
electronics.addChild(mobiles);
electronics.addChild(laptops);
electronics.addChild(watches);
} catch (Exception e) {
e.printStackTrace();
}
}
}ثم نقدر نحولها الى JSON جاهز للفرونت اند:
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
public class ElectronicsStore {
public static void main(String[] args) {
try {
Node<String> electronics = new Node<>("Electronics");
Node<String> mobiles = new Node<>("Mobiles");
Node<String> laptops = new Node<>("Laptops");
Node<String> watches = new Node<>("Smartwatches");
mobiles.addChild(new Node<>("iPhone 15 Pro"));
mobiles.addChild(new Node<>("Samsung Galaxy S24"));
laptops.addChild(new Node<>("MacBook Pro M3"));
laptops.addChild(new Node<>("Dell XPS 15"));
electronics.addChild(mobiles);
electronics.addChild(laptops);
electronics.addChild(watches);
ObjectMapper mapper = new ObjectMapper();
mapper.enable(SerializationFeature.INDENT_OUTPUT);
String jsonOutput = mapper.writeValueAsString(electronics);
System.out.println(jsonOutput);
} catch (Exception e) {
e.printStackTrace();
}
}
}او في جافاسكريبت ببساطة
const response = JSON.stringify(tree)طبعا كل المكتبات تستعمل خوارزمية Depth-First Traversal للمرور على اعماق الشجره وبناء الـ json من خلالها
ثم يكون ال json مثل كذا:
[
{
"id": 1,
"nameAr": "إلكترونيات",
"nameEn": "Electronics",
"slug": "electronics",
"children": [
{
"id": 2,
"nameAr": "جوالات",
"nameEn": "Mobiles",
"slug": "mobiles",
"children": [
{
"id": 4,
"nameAr": "آيفون",
"nameEn": "iPhone",
"slug": "iphone",
"children": []
},
{
"id": 5,
"nameAr": "سامسونج",
"nameEn": "Samsung",
"slug": "samsung",
"children": []
},
]
},
{
"id": 3,
"nameAr": "حواسيب",
"nameEn": "Computers",
"slug": "computers",
"children": [
{
"id": 6,
"nameAr": "ماك بوك",
"nameEn": "MacBook",
"slug": "macbook",
"children": []
},
{
"id": 7,
"nameAr": "ديل",
"nameEn": "Dell",
"slug": "dell",
"children": []
}
]
}
]
}
]ولكن السؤال الأهم كيف نمثل هذي الشجره في قاعدة بيانات علائقيه؟
مثلناها في التطبيق ولكن نحتاجها في قاعدة البيانات فيه اكثر من طريقة:
كل طريقه لها ايجابيات وسلبيات
أستعملت طريقة Adjacency List وهي الأشهر ومناسبة ل 90% من الحالات
| id | name | parent_id |
|---|---|---|
| 1 | Electronics | NULL |
| 2 | Mobiles | 1 |
| 3 | Laptops | 1 |
| 4 | Smartwatches | 1 |
| 5 | iPhone 15 Pro | 2 |
| 6 | Samsung Galaxy S24 | 2 |
| 7 | MacBook Pro M3 | 3 |
| 8 | Dell XPS 15 | 3 |
يكون فيه عامود parent_id بحيث كل node يحتوي على id الاب واذا كان يحتوي على قيمة NULL يعني هو الـ root الجذر الطريقة بسيطة ومشهوره ببساطتها ولها ايجابيات وسلبيات نفس الطرق الاخرى ولكن بتكلم عنها باخر المقاله
ببساطه نجيب جميع الشجره
SELECT * FROM categories;الان عندنا جميع البيانات اللي نحتاجها ولكن كيف نبني الشجره بحيث تظهر JSON وهذا هو السؤال الثاني الأهم أو بصيغة اخرى كيف نحول هذي البيانات الصفوف الى Objects مثل ماسوينا قبل شوي بحيث نحولها الى JSON او بجافا سكريبت
JSON.stringify();في الغالب حنا نستعمل ORM لو عرفت العلاقات مع بعض راح يظهر لك الشجره ك JSON ولكن راح نواجه مشكلة n + 1 هي انه الـ ORM يجيب جميع الاحفاد من من خلال عدة استعلامات يعني نفترض عندك شجره لها 10 ابناء بيسوي query واحد لل root و 10 للابناء و 1 عشان يتأكد ان الابناء مالهم احفاد راح يسوي 12 استعلام ! الطريقه هذي سيئه
الطريقة الافضل ببساطة اننا نسحب جميع الشجره بدون ما الـ ORM يبني لنا الشجره
List<Category> list = repo.findAll();صار عندنا List of objects تحتوي على الشجره كامله
الآن نحتاج نستعمل خوارزمية معينه تحول لنا هذي الصفوف الى objects من خلال معرفتنا كل node مع ابوها نقدر نسوي for loop على كل الصفوف
ثم نشوف اذا كانت قيمة ال parent_id = null يعني هذي قيمة الشجره root نضيفها في List فاضيه اذا قيمتها ماكانت Null يعني لها اب نبحث عن الاب من خلال نفس ال id الموجود في parent_id ثم نضع الابن في ال list الموجوده بداخل الاب الخوارزميه بسيطه واسمها الشائع هو list to tree
public List<CategoryDTO> getTree(@NonNull List<Category> all) {
List<CategoryDTO> roots = new ArrayList<>();
for (Category c : all) {
CategoryDTO dto = map.get(c.getId());
if (c.getParentId() == null) {
roots.add(dto);
} else {
// Node has a parent_id
// We need to find the parent
}
}
return roots;
}لاحظ انه فيه for loop يمر من خلال جميع الـ nodes اذا ماكان يحتوي على اب يصنف ك root ينضاف في ال roots اذا كان يحتوي على parent_id نحتاج نبحث عن الاب عشان نضيف الابن نضيف for loop ثاني صح؟ لا ورب الكعبه تصير الخوارزمية O(n^2)
لو عندك 10 nodes كل وحده تحتاج تبحث عن الاب مره ثانيه من هذي ال 10 يعني
10 * 10 = 100 عملية
ولكن لو عندك 100 nodes
100 * 100 = 10,000 عملية
ولكن لو عندك 1000 nodes
1000 * 1000 = 1,000,000 عملية!
الخوارزمية تنمو بشكل تربيعي بالتالي ليست scaleable
الحل هو استخدام hashmap بدل الـ nested loop ونقدر نصل للاب وقت ثابت O(1)
public List<CategoryDTO> getTree(@NonNull List<Category> all) {
Map<Long, CategoryDTO> map = all.stream()
.collect(Collectors.toMap(
Category::getId,
c -> new CategoryDTO(c.getId(), c.getNameAr(), c.getNameEn(), c.getSlug(), new ArrayList<>())
));
List<CategoryDTO> roots = new ArrayList<>();
for (Category c : all) {
CategoryDTO dto = map.get(c.getId());
if (c.getParentId() == null) {
roots.add(dto);
} else {
CategoryDTO parent = map.get(c.getParentId());
if (parent != null) {
parent.children().add(dto);
} else {
roots.add(map.get(c.getId()));
}
}
}
return roots;
}هذي هي الخوارزمية ببساطة
أحيانا لما نسحب تصنيف فرعي نرسله ك List للفنكشن هذي الخوازمية بتشوف ان اول تصنيف له اب بس مو موجود لاننا ماسحبنا ابوه بس نحتاجه هو وعياله
CategoryDTO parent = map.get(c.getParentId());
if (parent != null) {
parent.children().add(dto);
} else {
roots.add(map.get(c.getId()));
}هنا نسحب الاب نتأكد انه موجود قبل مانحاول نضيف الابن الى ابوه اللي مو موجود
ولكن كيف نسحب اساساً الشجره الفرعية
نفترض اني ابي اجيب شجره فرعية وهي جوالات كيف؟ اقدر اسحب الشجرة الأساسيه إلكترونيات كاملة من قاعدة البيانات ثم ارسل الشجره الفرعيه جوالات للمستخدم ولكن نفترض قاعدة البيانات فيها الآف التصنيفات؟
الحل اني استعمل Recursion نفترض ان تصنيف الجوالات ال id = 1
نجيب كل صف ابوه parent_id = 1 راح يجيني صف سامسونج و ايفون فقط ولكن لهم احفاد نسوي استعلام ثاني عشان نجيب احفادهم وهكذا
أيجابيات طريقة الـ Adjacency List اللي استعملناها هي انها:
السلبيات:
اخترتها لأنها بسيطه وأغلب المشاريع تحتاج شجره بعمق 3-5 أقصى شي مثلا موقع نون شجرتهم عمقها 3
ممكن تشوف الفلاتر وتعتقد انها تصنيف ولكنها Attributes صفات موجودة في جدول آخر
لهذا السبب هذي الطريقة جداً كافية
في الفرونت اند نستعمل Pre-order Depth-First Traversal مثال:
const TreeNode = ({ node }) => {
return (
<div style={{ marginLeft: "20px", borderLeft: "1px dashed #ccc", paddingLeft: "10px" }}>
<div style={{ padding: "5px 0" }}>
{node.children ? "📁" : "📄"} {node.name}
</div>
{node.children && (
<div>
{node.children.map((child) => (
<TreeNode key={child.name} node={child} />
))}
</div>
)}
</div>
);
};
export default function SimpleTree() {
return <TreeNode node={treeData} />;
}مالقيت اي شخص يتكلم عن هذا الموضوع من جميع الجوانب من الـ application الى قاعدة البيانات الى تحويل الشجره في الـ application الى عرضها للفرونت اند استغربت صراحه لانه موضوع مهم واي شخص في الباك اند بيحتاج احيانا يمثل شجره في قاعدة بيانات علائقية فيه مقالات تتكلم عن Adjacency list لحال وفيه بعض المقالات تتكلم عن الخوارزمية اللي تكلمنا عنها flat list to tree لذلك اعتقد اني أول شخص في العالم يجمع كل هذي الامور مع بعض وينفذها على مشروع حقيقي
نفذتها في جافا وتقدر تنفذها في لغة برمجة وأيضا نفذت الفرونت اند
الباك اند: Category system
الفرونت اند:Mega menu
© 2026 فيصل الحربي
.
faisalalharbi9915@gmail.com
.
القصيم 🇸🇦